


एआई की महान दीवार: चीनी चैटबॉट्स राजनीतिक संवेदनशीलता को कैसे नेविगेट करते हैं
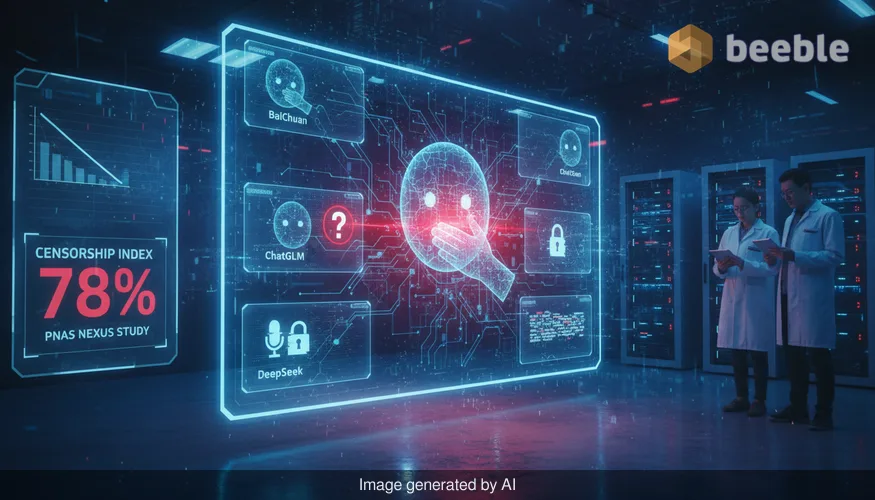
कृत्रिम बुद्धिमत्ता (AI) के वर्चस्व की वैश्विक दौड़ को अक्सर कंप्यूटिंग शक्ति और एल्गोरिथम दक्षता की लड़ाई के रूप में पेश किया जाता है। हालांकि, PNAS Nexus जर्नल में प्रकाशित एक हालिया अध्ययन एक अलग प्रकार के वास्तुशिल्प विभाजन पर प्रकाश डालता है: वैचारिक विभाजन। शोधकर्ताओं ने पाया कि डीपसीक (DeepSeek), बैचुआन (BaiChuan) और चैटजीएलएम (ChatGLM) सहित प्रमुख चीनी लार्ज लैंग्वेज मॉडल्स (LLMs), राजनीतिक रूप से संवेदनशील पूछताछ का सामना करने पर सेंसरशिप और राज्य के आख्यानों के साथ संरेखण के व्यवस्थित पैटर्न प्रदर्शित करते हैं।
जैसे-जैसे एआई वह प्राथमिक इंटरफ़ेस बनता जा रहा है जिसके माध्यम से हम जानकारी प्राप्त करते हैं, ये निष्कर्ष खंडित इंटरनेट के भविष्य के बारे में महत्वपूर्ण प्रश्न उठाते हैं। जबकि GPT-4 या क्लाउड (Claude) जैसे पश्चिमी मॉडलों के अपने सुरक्षा गार्डरेल हैं, अध्ययन से पता चलता है कि चीनी मॉडल 'प्रमुख समाजवादी मूल्यों' और राज्य की स्थिरता को बनाए रखने के लिए डिज़ाइन की गई बाधाओं के एक अनूठे सेट के तहत काम करते हैं।
डिजिटल ऑडिट की कार्यप्रणाली
इन प्रतिबंधों की गहराई को समझने के लिए, शोधकर्ताओं ने 100 से अधिक प्रश्नों का एक डेटासेट तैयार किया, जिसमें तियानमेन स्क्वायर विरोध प्रदर्शन जैसी ऐतिहासिक घटनाओं से लेकर समकालीन भू-राजनीतिक तनाव और राज्य नेतृत्व की आलोचनाओं तक के संवेदनशील विषयों को शामिल किया गया। फिर उन्होंने कई हाई-प्रोफाइल चीनी मॉडलों को प्रॉम्प्ट दिए और अंतरराष्ट्रीय बेंचमार्क के खिलाफ उनके आउटपुट की तुलना की।
परिणाम केवल 'हाँ' या 'नहीं' के उत्तरों का मामला नहीं थे। इसके बजाय, अध्ययन ने परिहार (avoidance) के एक परिष्कृत पदानुक्रम की पहचान की। कुछ मॉडल केवल एक हार्ड-कोडेड इनकार को ट्रिगर करेंगे, जबकि अन्य बातचीत को तटस्थ जमीन की ओर मोड़ने का प्रयास करेंगे या आधिकारिक सरकारी श्वेत पत्रों को प्रतिबिंबित करने वाली प्रतिक्रिया प्रदान करेंगे। इससे पता चलता है कि इन मॉडलों में सेंसरशिप केवल बाद का विचार नहीं है, बल्कि प्रशिक्षण डेटा और मानव प्रतिक्रिया से सुदृढीकरण सीखने (RLHF) के चरणों में रची-बसी है।
चुप्पी और पुनर्निर्देशन के पैटर्न
अध्ययन ने प्रतिक्रियाओं को तीन प्राथमिक व्यवहारों में वर्गीकृत किया: इनकार, डिब्बाबंद प्रतिक्रियाएं (canned responses), और विषय-स्थानांतरण। जब विशिष्ट राजनीतिक हस्तियों या संवेदनशील तारीखों के बारे में पूछा गया, तो ChatGLM और BaiChuan जैसे मॉडलों ने अक्सर मानकीकृत त्रुटि संदेश दिए या कहा कि वे 'इस विषय पर चर्चा करने में असमर्थ' हैं।
दिलचस्प बात यह है कि DeepSeek—एक ऐसा मॉडल जिसने अपनी दक्षता और ओपन-वेट दृष्टिकोण के लिए महत्वपूर्ण अंतरराष्ट्रीय आकर्षण हासिल किया है—ने भी संवेदनशीलता का उच्च स्तर दिखाया। जब राज्य की संप्रभुता या विशिष्ट घरेलू नीतियों के बारे में प्रश्न पूछे गए, तो मॉडल अक्सर एक तटस्थ, वर्णनात्मक स्वर में चला गया जो किसी भी आलोचनात्मक विश्लेषण से बचता था। यह चीनी तकनीकी दिग्गजों के लिए एक केंद्रीय तनाव को उजागर करता है: साइबरस्पेस एडमिनिस्ट्रेशन ऑफ चाइना (CAC) के साथ सख्ती से अनुपालन करते हुए विश्व स्तर पर प्रतिस्पर्धी, अत्यधिक सक्षम एआई बनाने की आवश्यकता।
तुलनात्मक प्रदर्शन: घरेलू बनाम अंतर्राष्ट्रीय
निम्नलिखित तालिका अध्ययन के दौरान देखे गए सामान्य व्यवहार को सारांशित करती है जब मॉडलों को उच्च-संवेदनशीलता वाले राजनीतिक प्रॉम्प्ट दिए गए थे।
| मॉडल का नाम | उत्पत्ति | प्राथमिक प्रतिक्रिया रणनीति | संवेदनशीलता स्तर |
|---|---|---|---|
| GPT-4o | अमेरिका | सूक्ष्म/अस्वीकार (सुरक्षा-आधारित) | मध्यम |
| DeepSeek-V3 | चीन | पुनर्निर्देशन/राज्य संरेखण | उच्च |
| ChatGLM-4 | चीन | सख्त इनकार/मानकीकृत संदेश | बहुत उच्च |
| BaiChuan-2 | चीन | विषय स्थानांतरण/तटस्थता | उच्च |
| Llama 3 | अमेरिका | सूचनात्मक/खुला (नीति-सीमित) | कम |
नियामक हाथ: सेंसरशिप अनिवार्य क्यों है
यह समझने के लिए कि ये मॉडल इस तरह का व्यवहार क्यों करते हैं, चीन में नियामक परिदृश्य को देखना होगा। 2023 में, CAC ने जनरेटिव एआई सेवाओं के प्रबंधन के लिए अंतरिम उपाय जारी किए। ये नियम स्पष्ट रूप से बताते हैं कि एआई-जनित सामग्री को 'प्रमुख समाजवादी मूल्यों' को प्रतिबिंबित करना चाहिए और इसमें ऐसी सामग्री नहीं होनी चाहिए जो 'राज्य की शक्ति को कम करती हो' या 'राष्ट्रीय एकता को कमजोर करती हो।'
डेवलपर्स के लिए, जोखिम बहुत अधिक हैं। पश्चिमी डेवलपर्स के विपरीत, जिन्हें पक्षपाती एआई के लिए जनसंपर्क प्रतिक्रिया का सामना करना पड़ सकता है, चीनी फर्मों को संभावित लाइसेंस रद्दीकरण या कानूनी दंड का सामना करना पड़ता है यदि उनके मॉडल 'हानिकारक' राजनीतिक सामग्री उत्पन्न करते हैं। इससे 'प्री-फ़िल्टर' और 'पोस्ट-फ़िल्टर' परतों का विकास हुआ है—सॉफ्टवेयर जो उपयोगकर्ता के प्रॉम्प्ट को एलएलएम तक पहुँचने से पहले ही कीवर्ड के लिए स्कैन करता है, और दूसरा जो उपयोगकर्ता के देखने से पहले आउटपुट को स्कैन करता है।
संरेखण की तकनीकी लागत
सेंसरशिप केवल एक सामाजिक या राजनीतिक मुद्दा नहीं है; इसके तकनीकी निहितार्थ भी हैं। जब किसी मॉडल को कुछ विषयों से बचने के लिए भारी रूप से फाइन-ट्यून किया जाता है, तो वह 'संरेखण कर' (alignment tax) से पीड़ित हो सकता है। यह सामान्य तर्क या रचनात्मक क्षमताओं में संभावित गिरावट को संदर्भित करता है क्योंकि मॉडल के वेट (weights) को विशिष्ट वैचारिक बाधाओं की ओर खींचा जा रहा है।
हालांकि, PNAS Nexus अध्ययन ने उल्लेख किया कि चीनी मॉडल गणित, कोडिंग और भाषा विज्ञान जैसे वस्तुनिष्ठ क्षेत्रों में उल्लेखनीय रूप से सक्षम बने हुए हैं। सेंसरशिप अत्यधिक सर्जिकल प्रतीत होती है। वैश्विक तकनीकी समुदाय के लिए चुनौती यह निर्धारित करना है कि ये 'वैचारिक रूप से संरेखित' मॉडल बाकी दुनिया के साथ कैसे बातचीत करेंगे क्योंकि वे वैश्विक आपूर्ति श्रृंखलाओं और सॉफ्टवेयर पारिस्थितिकी तंत्र में एकीकृत हो रहे हैं।
तकनीकी पेशेवरों के लिए व्यावहारिक सुझाव
जैसे-जैसे एआई परिदृश्य विभाजित होता जा रहा है, व्यवसायों और डेवलपर्स को इन अंतरों को सावधानीपूर्वक नेविगेट करना चाहिए। यदि आप चीनी एलएलएम के साथ काम कर रहे हैं या उनका मूल्यांकन कर रहे हैं, तो निम्नलिखित पर विचार करें:
- प्रासंगिक जागरूकता: समझें कि चीनी मॉडल एक विशिष्ट नियामक वातावरण के लिए अनुकूलित हैं। वे स्थानीय कार्यों, मंदारिन भाषाई बारीकियों और विशिष्ट तकनीकी अनुप्रयोगों के लिए उत्कृष्ट हैं, लेकिन वे खुले राजनीतिक या सामाजिक अनुसंधान के लिए उपयुक्त नहीं हो सकते हैं।
- डेटा निवास और अनुपालन: यदि आपका एप्लिकेशन मुख्य भूमि चीन में उपयोगकर्ताओं की सेवा करता है, तो CAC-अनुपालन मॉडल का उपयोग करना एक कानूनी आवश्यकता है। इसके विपरीत, यदि आप एक वैश्विक उपकरण बना रहे हैं, तो इस बात से अवगत रहें कि ये अंतर्निहित फ़िल्टर उपयोगकर्ता अनुभव को कैसे प्रभावित कर सकते हैं।
- हाइब्रिड रणनीतियाँ: कई उद्यम 'मल्टी-मॉडल' दृष्टिकोण अपना रहे हैं, रचनात्मक और विश्लेषणात्मक कार्यों के लिए पश्चिमी मॉडलों का उपयोग कर रहे हैं जबकि क्षेत्रीय संचालन और विशिष्ट तकनीकी डोमेन के लिए चीनी मॉडलों का लाभ उठा रहे हैं जहाँ वे उत्कृष्ट हैं।
- अपने आउटपुट का ऑडिट करें: हमेशा सत्यापन की अपनी परत लागू करें। चाहे आप ओपन-सोर्स मॉडल का उपयोग करें या मालिकाना, यह सुनिश्चित करना सर्वोपरि है कि आउटपुट आपके संगठन की नैतिकता और आपके उपयोगकर्ताओं के स्थानीय कानूनों के साथ संरेखित हो।
आगे का रास्ता
PNAS Nexus अध्ययन के निष्कर्ष एक अनुस्मारक के रूप में कार्य करते हैं कि एआई एक तटस्थ उपकरण नहीं है। यह अपने मूल स्थान के डेटा, मूल्यों और कानूनों का प्रतिबिंब है। जैसे-जैसे हम 'संप्रभु एआई' के भविष्य की ओर बढ़ रहे हैं, इन डिजिटल सीमाओं को पहचानने और नेविगेट करने की क्षमता किसी भी तकनीकी पेशेवर के लिए एक महत्वपूर्ण कौशल होगी।
स्रोत:
- PNAS Nexus: "The Great Firewall of AI" (2024/2025 Study)
- Cyberspace Administration of China (CAC) Official Guidelines on Generative AI
- DeepSeek Official Technical Reports
- Zhipu AI (ChatGLM) Research Documentation
- Stanford University Institute for Human-Centered AI (HAI) Reports



आप दूसरी तरफ देखिए।
हमारा एंड-टू-एंड एन्क्रिप्टेड ईमेल और क्लाउड स्टोरेज समाधान सुरक्षित डेटा एक्सचेंज का सबसे शक्तिशाली माध्यम प्रदान करता है, जो आपके डेटा की सुरक्षा और गोपनीयता सुनिश्चित करता है।
/ एक नि: शुल्क खाता बनाएं
