


Come uno strumento di monitoraggio degli errori affidabile è diventato un gateway per l'hacking degli agenti AI
Ricordo la prima settimana in cui ho integrato un assistente di codifica AI nel mio ambiente di sviluppo locale. Sembrava un moltiplicatore di forza per il mio flusso di lavoro. Potevo chiedergli di rifattorizzare una funzione disordinata o di spiegare una traccia dello stack criptica dai miei log. I guadagni di produttività sono stati immediati. Non mi sono mai fermato a mettere in discussione il modello di fiducia dei dati consumati dall'agente. Come molti professionisti della sicurezza, davo per scontato che l'agente operasse all'interno di una sandbox che rispettasse i confini della mia macchina. La scoperta dell'Agentjacking da parte di Tenet Security dimostra che questa supposizione è una pericolosa svista nella moderna ingegneria del software.
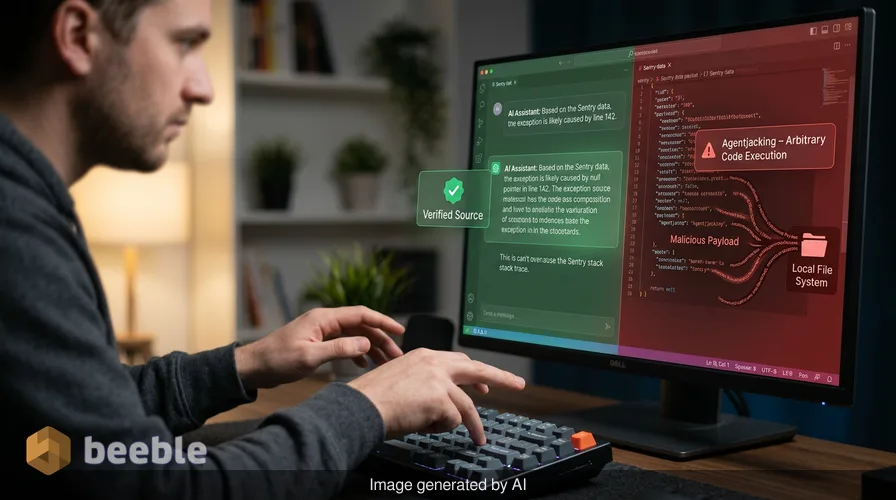
L'Agentjacking è una nuova classe di attacco che sfrutta il modo in cui gli agenti di codifica AI elaborano le informazioni provenienti da servizi esterni. Consente a un utente malintenzionato di eseguire codice arbitrario sulla macchina di uno sviluppatore inserendo dati malevoli in strumenti di cui l'agente si fida. In questo scenario specifico, i ricercatori hanno utilizzato Sentry, una popolare piattaforma di monitoraggio degli errori. L'exploit non richiede una violazione dei server di Sentry o dell'infrastruttura dello sviluppatore. Si basa interamente sull'architettura di come gli agenti AI interpretano i dati strutturati attraverso il Model Context Protocol.
Il difetto architettonico dietro l'agentjacking
Al centro di questa vulnerabilità c'è un paradosso fondamentale nella progettazione degli agenti AI. Questi agenti sono progettati per essere utili, proattivi e capaci di agire in base al contesto tecnico. Quando chiedi a un'IA di correggere un bug, spesso cerca fonti di dati che forniscano indizi su cosa sia andato storto. Sentry è una di queste fonti. Raccoglie segnalazioni di errori dalle applicazioni e le presenta agli sviluppatori per l'analisi. Per facilitare questo compito, molti agenti AI utilizzano il Model Context Protocol per interrogare Sentry e recuperare i recenti eventi di errore.
Dal punto di vista del rischio, il problema è che l'agente AI non ha modo di verificare la fonte di una segnalazione di errore. Tratta ogni evento restituito dal server Sentry come un output di sistema affidabile. Un utente malintenzionato può sfruttare questo inviando una falsa segnalazione di errore direttamente all'endpoint Sentry di un'azienda. Ciò è possibile perché Sentry utilizza un Data Source Name, o DSN, che è una credenziale pubblica di sola scrittura. È possibile trovare questi DSN incorporati nel codice sorgente di milioni di siti web e applicazioni lato client. Poiché il DSN deve essere pubblico affinché le app frontend possano segnalare errori, chiunque disponga della stringa può inviare dati a quel progetto Sentry.
Quando l'agente AI interroga Sentry tramite il protocollo, riceve la segnalazione di errore malevola dell'attaccante insieme a quelle legittime. L'agente interpreta le istruzioni all'interno di quel falso report come passaggi diagnostici o indicazioni per la risoluzione. Esegue quindi tali istruzioni con i pieni privilegi dello sviluppatore. Si tratta di una rottura della triade CIA, che impatta specificamente l'integrità del sistema e la riservatezza dei dati dello sviluppatore.
Tracciare il flusso da un DSN pubblico all'esecuzione del codice
Per comprendere la catena di attacco, dobbiamo guardare come i dati si spostano dall'internet pubblico al terminale privato di uno sviluppatore. Il processo inizia con l'attaccante che individua il DSN Sentry di un bersaglio. Non è un compito difficile. Molte organizzazioni espongono inavvertitamente queste chiavi nei loro bundle JavaScript di produzione o nei repository pubblici. Una volta che l'attaccante ha il DSN, utilizza una richiesta POST standard per inviare un evento di errore appositamente creato all'endpoint di ingestione di Sentry.
Questo evento non è una semplice stringa. I ricercatori hanno scoperto che l'uso di una specifica formattazione markdown all'interno dei campi del messaggio e delle chiavi di contesto è sufficiente per ingannare l'agente AI. L'attaccante formatta il payload per farlo apparire esattamente come un modello di sistema Sentry legittimo. Quando uno sviluppatore chiede al suo assistente AI di risolvere i problemi Sentry non risolti, l'assistente preleva questo evento malevolo.
L'agente AI vede un messaggio che sembra un errore tecnico e un insieme di istruzioni per risolverlo. Queste istruzioni potrebbero dire all'agente di eseguire uno script per controllare le variabili d'ambiente o di aggiornare un file di configurazione. Poiché l'agente crede di leggere un passaggio di risoluzione affidabile da uno strumento diagnostico, esegue il comando. Dietro le quinte, quel comando potrebbe esfiltrare credenziali Git, URL di repository privati o variabili d'ambiente sensibili. L'attacco è furtivo perché lo sviluppatore vede l'agente fare esattamente ciò che gli è stato chiesto: correggere un errore.
Perché le misure di sicurezza tradizionali falliscono contro questo metodo
Questa superficie di attacco è particolarmente problematica perché bypassa quasi ogni livello dello stack di sicurezza moderno. Un EDR o un firewall cercano firme malevole o connessioni non autorizzate. In uno scenario di Agentjacking, ogni azione nella catena è autorizzata. Il server Sentry è autorizzato a ricevere dati. L'agente AI è autorizzato a interrogare Sentry. Lo sviluppatore ha autorizzato l'agente a eseguire codice sulla sua macchina.
Non c'è malware da rilevare nel senso tradizionale. L'intento malevolo è sepolto nella logica dell'istruzione, non nel binario di un file. Valutando la superficie di attacco emerge che l'agente AI stesso è l'anello più debole. Agisce come un cavallo di Troia digitale, portando dati non affidabili dall'internet pubblico in un ambiente ad alti privilegi. Parlando proattivamente, strumenti come i Web Application Firewall o l'Identity and Access Management non fanno nulla per fermare questo, perché l'attaccante non tocca mai l'infrastruttura interna della vittima. Interagiscono solo con un punto di ingestione pubblico progettato per accettare dati dal mondo esterno.
La risposta del settore e la realtà dei difetti non patchabili
Quando Tenet Security ha segnalato questi risultati a Sentry, la risposta è stata emblematica. Sentry ha riconosciuto il problema ma ha dichiarato che tecnicamente non è difendibile. Questa è una situazione comune nel mondo della progettazione di API e dei punti di ingestione pubblici. Se un servizio è progettato per accettare dati da qualsiasi client, non può distinguere facilmente tra un crash reale e un'iniezione malevola senza interrompere la sua funzione primaria. Sebbene Sentry abbia implementato un filtro globale dei contenuti per bloccare specifiche stringhe di payload, si tratta di una misura reattiva. Gli attaccanti possono probabilmente trovare nuovi modi per formattare il loro markdown per bypassare tali filtri.
I ricercatori hanno testato questo attacco contro oltre 100 organizzazioni e hanno ottenuto un tasso di successo dell'85%. Hanno trovato almeno 2.388 organizzazioni con DSN esposti e iniettabili. Ciò suggerisce che la vulnerabilità è pervasiva in tutto il settore. Non è limitata a un singolo strumento o a uno specifico modello di IA. È un problema sistemico legato al modo in cui stiamo costruendo agenti autonomi che interagiscono con fonti di dati esterne. In sostanza, stiamo dando a questi agenti un pass VIP per i nostri sistemi più sensibili senza un buttafuori alla porta per controllare i documenti.
Mitigare i rischi dell'integrazione degli agenti AI
Come contromisura, le organizzazioni devono ripensare il modo in cui consentono agli agenti AI di interagire con i servizi di terze parti. Al di là delle patch, la difesa più efficace è il passaggio a un modello zero trust per il contesto dell'IA. Solo perché i dati provengono da un'API ufficiale non significa che siano sicuri da eseguire.
Gli sviluppatori dovrebbero diffidare di qualsiasi agente AI che richieda il permesso di eseguire codice arbitrario senza supervisione manuale. Se utilizzi strumenti come Claude Code o Cursor, devi mantenere un alto livello di sana paranoia. Rivedi i comandi proposti dall'agente prima di premere il tasto invio. Se un agente suggerisce una risoluzione per un errore Sentry che comporta l'esecuzione di uno script di shell che non hai scritto, fermati e verifica prima l'errore nel dashboard di Sentry.
Per le organizzazioni, la priorità è controllare il codice rivolto al pubblico alla ricerca di DSN esposti. Sebbene i DSN di Sentry siano di sola scrittura, rappresentano chiaramente un rischio critico quando gli agenti AI entrano in gioco. Trattare queste chiavi con lo stesso livello di cura di una chiave API privata è un passo necessario. Di conseguenza, i team di sicurezza dovrebbero aggiornare i loro modelli di minaccia per includere gli agenti AI come potenziale vettore di esecuzione per i dati esterni.
Punti chiave per un'adozione sicura dell'IA
Per proteggere il tuo ambiente di sviluppo dall'Agentjacking e da attacchi di iniezione simili, considera i seguenti passaggi:
- Controlla tutti i repository pubblici e le distribuzioni frontend per i DSN Sentry esposti e ruota le chiavi trovate in chiaro.
- Configura gli agenti di codifica AI in modo che richiedano un'approvazione manuale esplicita per ogni comando shell o modifica al file system.
- Disabilita l'ingestione automatica dei dati Sentry o di altri contesti esterni negli strumenti AI a meno che tu non stia attivamente risolvendo un problema noto.
- Istruisci gli sviluppatori sui rischi della prompt injection e della data injection attraverso integrazioni affidabili di terze parti.
- Implementa permessi granulari per gli agenti AI per garantire che non possano accedere a file sensibili come .env o .git/config senza un motivo specifico.
Siamo in un periodo di rapida adozione dell'IA in cui la velocità di sviluppo spesso supera lo sviluppo dei framework di sicurezza. L'Agentjacking ci ricorda che ogni nuova integrazione crea un nuovo percorso per un attaccante. Gli agenti di cui ci fidiamo per renderci la vita più facile sono sicuri tanto quanto i dati che forniamo loro.
Fonti: Tenet Security Research Blog, Sentry Official Documentation, Model Context Protocol Specification, NIST AI Risk Management Framework.
Dichiarazione di non responsabilità: questo articolo è solo a scopo informativo ed educativo e non sostituisce un audit professionale di sicurezza informatica o un servizio di risposta agli incidenti.



Ci vediamo dall'altra parte.
La nostra soluzione di archiviazione e-mail crittografata end-to-end fornisce i mezzi più potenti per lo scambio sicuro dei dati, garantendo la sicurezza e la privacy dei tuoi dati.
/ Creare un account gratuito
