


值得信赖的错误监控工具如何成为 AI 智能体劫持的入口
我记得在我将 AI 编程助手集成到本地开发环境的第一周,它感觉就像是我工作流的效率倍增器。我可以让它重构混乱的函数,或者解释日志中晦涩的堆栈跟踪。生产力的提升是立竿见影的。我从未停下来质疑过该智能体所消耗数据的信任模型。和许多安全从业者一样,我假设该智能体在一个尊重我机器边界的沙箱内运行。Tenet Security 对 Agentjacking(智能体劫持)的发现证明,这种假设是现代软件工程中一个危险的疏忽。
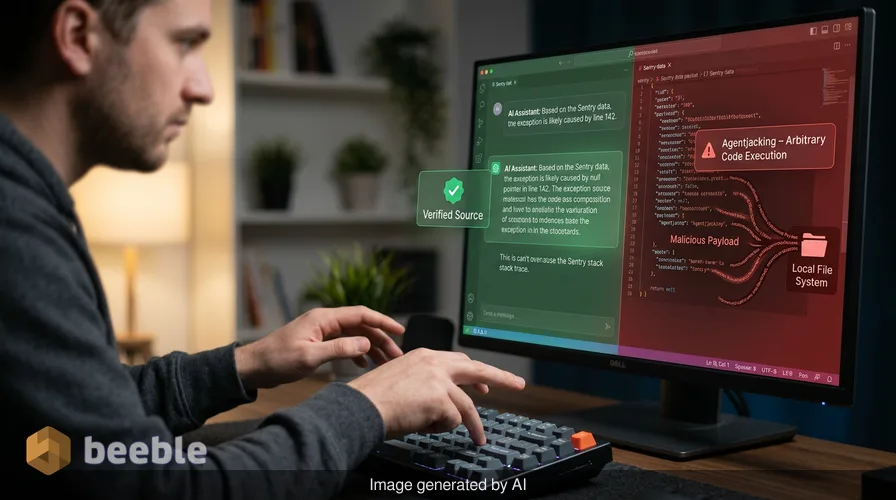
Agentjacking 是一种新型攻击,它利用了 AI 编程智能体处理来自外部服务信息的方式。攻击者通过向智能体信任的工具输入恶意数据,从而在开发者的机器上执行任意代码。在这个特定的场景中,研究人员使用了 Sentry,一个流行的错误跟踪平台。这种漏洞利用不需要攻破 Sentry 的服务器或开发者的基础设施。它完全依赖于 AI 智能体通过模型上下文协议(Model Context Protocol)解释结构化数据的架构。
Agentjacking 背后的架构缺陷
这一漏洞的核心在于 AI 智能体设计中的一个基本悖论。这些智能体被设计为乐于助人、积极主动,并能够根据技术上下文采取行动。当你要求 AI 修复一个错误时,它通常会寻找提供故障线索的数据源。Sentry 就是这样一个来源。它收集应用程序的错误报告,并将其呈现给开发者进行分析。为了简化这一过程,许多 AI 智能体使用模型上下文协议来查询 Sentry 并检索最近的错误事件。
从风险角度来看,问题在于 AI 智能体无法验证错误报告的来源。它将 Sentry 服务器返回的每个事件都视为受信任的系统输出。攻击者可以利用这一点,直接向公司的 Sentry 端点发送虚假的错误报告。这是可能的,因为 Sentry 使用数据源名称(DSN),这是一种公开的、只写的凭据。你可以在数百万个网站和客户端应用程序的源代码中找到这些嵌入的 DSN。因为 DSN 旨在公开以便前端应用报告错误,所以任何拥有该字符串的人都可以向该 Sentry 项目发送数据。
当 AI 智能体通过协议查询 Sentry 时,它会同时收到攻击者的恶意错误报告和合法的报告。智能体将虚假报告中的指令解释为诊断步骤或解决指南。然后,它以开发者的全部权限执行这些指令。这是对 CIA 三要素(机密性、完整性、可用性)的破坏,特别是影响了系统的完整性和开发者数据的机密性。
追踪从公开 DSN 到代码执行的流程
要理解攻击链,我们必须观察数据是如何从公共互联网进入开发者的私有终端的。过程始于攻击者定位目标的 Sentry DSN。这并非难事。许多组织不经意间在生产环境的 JavaScript 包或公共仓库中暴露了这些密钥。一旦攻击者获得了 DSN,他们就会使用标准的 POST 请求向 Sentry 摄取端点发送一个精心构造的错误事件。
这个事件不是一个简单的字符串。研究人员发现,在消息字段和上下文键中使用特定的 Markdown 格式足以欺骗 AI 智能体。攻击者将有效载荷格式化,使其看起来完全像一个合法的 Sentry 系统模板。当开发者要求其 AI 助手解决未处理的 Sentry 问题时,助手就会拉取这个恶意事件。
AI 智能体看到的是一条看起来像技术错误的消息和一套修复指令。这些指令可能会告诉智能体运行脚本来检查环境变量,或者更新配置文件。因为智能体相信它正在读取来自诊断工具的受信任解决步骤,所以它执行了命令。在幕后,该命令可能正在窃取 Git 凭据、私有仓库 URL 或敏感的环境变量。这种攻击具有隐蔽性,因为开发者看到智能体正在做他们要求它做的事情:修复错误。
为什么传统安全措施对这种方法失效
这种攻击面特别棘手,因为它绕过了现代安全栈的几乎每一层。EDR 或防火墙会寻找恶意签名或未经授权的连接。在 Agentjacking 场景中,链条中的每个动作都是经过授权的。Sentry 服务器被授权接收数据。AI 智能体被授权查询 Sentry。开发者已授权智能体在他们的机器上运行代码。
在传统意义上,没有恶意软件可供检测。恶意意图隐藏在指令的逻辑中,而不是文件的二进制文件中。评估攻击面可以发现,AI 智能体本身就是最薄弱的环节。它充当了数字特洛伊木马,将来自公共互联网的不受信任数据带入高权限环境。从主动防御的角度来看,Web 应用程序防火墙(WAF)或身份与访问管理(IAM)等工具无法阻止这种情况,因为攻击者从未触及受害者的内部基础设施。他们只与一个旨在接受全球数据的公共摄取点进行交互。
行业响应与不可修复缺陷的现实
当 Tenet Security 向 Sentry 报告这些发现时,对方的反应耐人寻味。Sentry 承认了这个问题,但表示这在技术上是无法防御的。这是 API 设计和公共摄取点领域常见的情况。如果一个服务被设计为接受来自任何客户端的数据,那么在不破坏其主要功能的情况下,它很难轻易区分真实的崩溃和恶意注入。虽然 Sentry 已经实施了全局内容过滤器来阻止特定的有效载荷字符串,但这只是一种被动措施。攻击者很可能会找到新的方法来格式化他们的 Markdown 以绕过此类过滤器。
研究人员针对 100 多个组织测试了这种攻击,并取得了 85% 的成功率。他们发现至少有 2,388 个组织暴露了可注入的 DSN。这表明该漏洞在整个行业中普遍存在。它不限于单一工具或特定的 AI 模型。这是一个系统性问题,涉及我们如何构建与外部数据源交互的自主智能体。我们本质上是在给这些智能体发放进入我们最敏感系统的 VIP 通行证,而门口却没有保镖来检查身份证。
降低 AI 智能体集成的风险
作为对策,组织必须重新思考他们如何允许 AI 智能体与第三方服务交互。撇开补丁不谈,最有效的防御是转向 AI 上下文的零信任模型。仅仅因为数据来自官方 API,并不意味着该数据可以安全执行。
开发者应该警惕任何请求在没有人工监督的情况下运行任意代码的 AI 智能体。如果你正在使用 Claude Code 或 Cursor 等工具,你必须保持高度的健康警惕。在按下回车键之前,审查智能体建议的命令。如果智能体建议针对 Sentry 错误运行一个你没写过的 Shell 脚本,请先停止并在 Sentry 仪表板中验证该错误。
对于组织而言,首要任务是审计面向公众的代码以查找暴露的 DSN。虽然 Sentry DSN 是只写的,但当 AI 智能体参与其中时,它们显然代表了任务关键型的风险。像对待私有 API 密钥一样谨慎对待这些密钥是必要的一步。因此,安全团队应该更新其威胁模型,将 AI 智能体视为外部数据的潜在执行向量。
安全采用 AI 的关键要点
为了保护你的开发环境免受 Agentjacking 和类似注入攻击的侵害,请考虑以下步骤:
- 审计所有公共仓库和前端部署以查找暴露的 Sentry DSN,并轮换任何以明文形式发现的密钥。
- 配置 AI 编程智能体,要求对每个 Shell 命令或文件系统更改进行显式的人工批准。
- 除非你正在主动调试已知问题,否则在 AI 工具中禁用 Sentry 数据或其他外部上下文的自动摄取。
- 教育开发者了解通过受信任的第三方集成进行提示词注入和数据注入的风险。
- 为 AI 智能体实施细粒度权限,确保它们在没有特定理由的情况下无法访问 .env 或 .git/config 等敏感文件。
我们正处于 AI 快速采用的时期,开发速度往往超过了安全框架的发展速度。Agentjacking 提醒我们,每一次新的集成都会为攻击者创造一条新路径。我们信任的、旨在让我们的生活更轻松的智能体,其安全性仅取决于我们喂给它们的数据。
来源:Tenet Security Research Blog, Sentry Official Documentation, Model Context Protocol Specification, NIST AI Risk Management Framework.
免责声明:本文仅供信息参考和教育目的,不替代专业的网络安全审计或事件响应服务。




