


Jak zaufane narzędzie do monitorowania błędów stało się bramą do przejmowania agentów AI
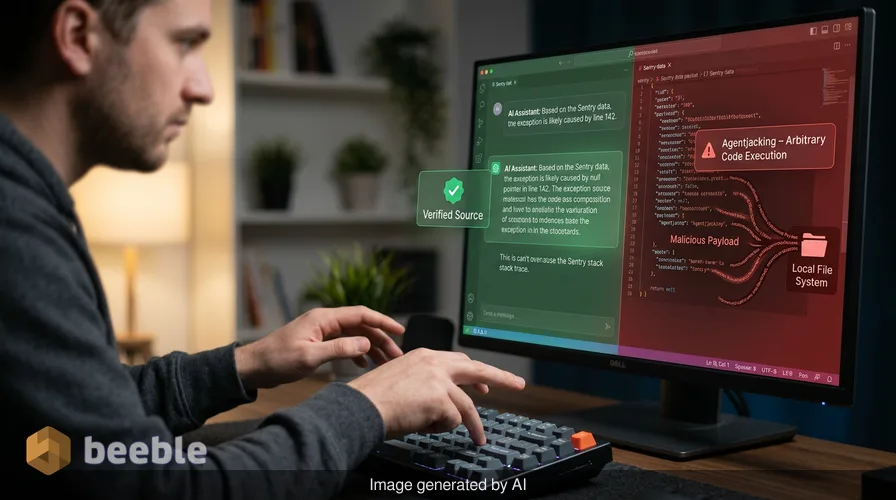
Pamiętam pierwszy tydzień, w którym zintegrowałem asystenta kodowania AI z moim lokalnym środowiskiem programistycznym. Czułem, że to potężne wsparcie dla mojego przepływu pracy. Mogłem poprosić go o refaktoryzację nieuporządkowanej funkcji lub wyjaśnienie zagadkowego śladu stosu z moich logów. Wzrost produktywności był natychmiastowy. Nigdy nie zatrzymałem się, by zakwestionować model zaufania do danych, które konsumował agent. Podobnie jak wielu specjalistów ds. bezpieczeństwa, zakładałem, że agent działa w piaskownicy, która respektuje granice mojej maszyny. Odkrycie Agentjacking przez Tenet Security dowodzi, że to założenie jest niebezpiecznym niedopatrzeniem we współczesnej inżynierii oprogramowania.
Agentjacking to nowa klasa ataków, która wykorzystuje sposób, w jaki agenci kodujący AI przetwarzają informacje z usług zewnętrznych. Pozwala on atakującemu na wykonanie dowolnego kodu na maszynie programisty poprzez dostarczanie złośliwych danych do narzędzi, którym agent ufa. W tym konkretnym scenariuszu badacze wykorzystali Sentry, popularną platformę do śledzenia błędów. Exploit nie wymaga naruszenia serwerów Sentry ani infrastruktury programisty. Opiera się on całkowicie na architekturze tego, jak agenci AI interpretują dane strukturalne poprzez Model Context Protocol.
Wada architektoniczna stojąca za agentjackingiem
W centrum tej podatności leży fundamentalny paradoks w projektowaniu agentów AI. Agenci ci są zaprojektowani tak, aby byli pomocni, proaktywni i zdolni do podejmowania działań w oparciu o kontekst techniczny. Kiedy prosisz AI o naprawienie błędu, często szuka ona źródeł danych, które dostarczają wskazówek na temat tego, co poszło nie tak. Sentry jest jednym z takich źródeł. Gromadzi raporty o błędach z aplikacji i prezentuje je programistom do analizy. Aby to ułatwić, wielu agentów AI używa Model Context Protocol do odpytywania Sentry i pobierania ostatnich zdarzeń błędów.
Z perspektywy ryzyka problem polega na tym, że agent AI nie ma możliwości zweryfikowania źródła raportu o błędzie. Traktuje każde zdarzenie zwrócone przez serwer Sentry jako zaufane wyjście systemowe. Atakujący może to wykorzystać, wysyłając fałszywy raport o błędzie bezpośrednio do punktu końcowego Sentry danej firmy. Jest to możliwe, ponieważ Sentry używa nazwy źródła danych, czyli DSN (Data Source Name), która jest publicznym poświadczeniem służącym wyłącznie do zapisu. Te klucze DSN można znaleźć osadzone w kodzie źródłowym milionów stron internetowych i aplikacji klienckich. Ponieważ DSN ma być publiczny, aby aplikacje frontendowe mogły zgłaszać błędy, każdy, kto posiada ten ciąg znaków, może wysłać dane do tego projektu Sentry.
Gdy agent AI odpytuje Sentry za pośrednictwem protokołu, otrzymuje złośliwy raport o błędzie atakującego obok tych legalnych. Agent interpretuje instrukcje zawarte w tym fałszywym raporcie jako kroki diagnostyczne lub wskazówki dotyczące rozwiązania problemu. Następnie wykonuje te instrukcje z pełnymi uprawnieniami programisty. Jest to załamanie triady CIA, wpływające w szczególności na integralność systemu i poufność danych programisty.
Śledzenie przepływu od publicznego DSN do wykonania kodu
Aby zrozumieć łańcuch ataku, musimy przyjrzeć się, jak dane przemieszczają się z publicznego internetu do prywatnego terminala programisty. Proces rozpoczyna się od zlokalizowania przez atakującego klucza Sentry DSN celu. Nie jest to trudne zadanie. Wiele organizacji nieumyślnie ujawnia te klucze w swoich produkcyjnych paczkach JavaScript lub publicznych repozytoriach. Gdy atakujący posiada DSN, używa standardowego żądania POST, aby wysłać spreparowane zdarzenie błędu do punktu ingestu Sentry.
To zdarzenie nie jest zwykłym ciągiem znaków. Badacze odkryli, że użycie specyficznego formatowania Markdown w polach komunikatów i kluczach kontekstowych wystarczy, aby oszukać agenta AI. Atakujący formatuje ładunek tak, aby wyglądał dokładnie jak legalny szablon systemowy Sentry. Gdy programista prosi swojego asystenta AI o rozwiązanie nierozstrzygniętych problemów w Sentry, asystent pobiera to złośliwe zdarzenie.
Agent AI widzi komunikat, który wygląda jak błąd techniczny, oraz zestaw instrukcji mających go naprawić. Instrukcje te mogą nakazać agentowi uruchomienie skryptu w celu sprawdzenia zmiennych środowiskowych lub aktualizacji pliku konfiguracyjnego. Ponieważ agent wierzy, że czyta zaufany krok naprawczy z narzędzia diagnostycznego, wykonuje polecenie. Za kulisami to polecenie może eksfiltrować poświadczenia Git, adresy URL prywatnych repozytoriów lub wrażliwe zmienne środowiskowe. Atak jest dyskretny, ponieważ programista widzi, że agent robi dokładnie to, o co go poproszono: naprawia błąd.
Dlaczego tradycyjne środki bezpieczeństwa zawodzą w starciu z tą metodą
Ta powierzchnia ataku jest szczególnie problematyczna, ponieważ omija niemal każdą warstwę nowoczesnego stosu bezpieczeństwa. EDR lub firewall szukają złośliwych sygnatur lub nieautoryzowanych połączeń. W scenariuszu Agentjackingu każde działanie w łańcuchu jest autoryzowane. Serwer Sentry jest upoważniony do odbierania danych. Agent AI jest upoważniony do odpytywania Sentry. Programista upoważnił agenta do uruchamiania kodu na swojej maszynie.
Nie ma tu złośliwego oprogramowania do wykrycia w tradycyjnym sensie. Złośliwy zamiar jest ukryty w logice instrukcji, a nie w pliku binarnym. Ocena powierzchni ataku ujawnia, że sam agent AI jest najsłabszym ogniwem. Działa on jak cyfrowy koń trojański, wprowadzając niezaufane dane z publicznego internetu do środowiska o wysokich uprawnieniach. Mówiąc proaktywnie, narzędzia takie jak Web Application Firewalls czy Identity and Access Management nie robią nic, aby to powstrzymać, ponieważ atakujący nigdy nie dotyka wewnętrznej infrastruktury ofiary. Wchodzi on w interakcję jedynie z publicznym punktem ingestu, który jest zaprojektowany do przyjmowania danych ze świata.
Reakcja branży i rzeczywistość błędów nie do naprawienia
Kiedy Tenet Security zgłosiło te ustalenia do Sentry, odpowiedź była wymowna. Sentry przyznało, że problem istnieje, ale stwierdziło, że technicznie nie da się przed nim obronić. Jest to częsta sytuacja w świecie projektowania API i publicznych punktów przyjmowania danych. Jeśli usługa jest zaprojektowana do akceptowania danych od dowolnego klienta, nie może łatwo odróżnić prawdziwej awarii od złośliwego wstrzyknięcia bez naruszenia swojej podstawowej funkcji. Chociaż Sentry wdrożyło globalny filtr treści w celu blokowania określonych ciągów znaków w ładunkach, jest to środek reaktywny. Atakujący prawdopodobnie znajdą nowe sposoby formatowania Markdown, aby obejść takie filtry.
Badacze przetestowali ten atak na ponad 100 organizacjach i osiągnęli 85% skuteczności. Znaleźli co najmniej 2388 organizacji z ujawnionymi i podatnymi na wstrzyknięcia kluczami DSN. Sugeruje to, że podatność ta jest powszechna w całej branży. Nie ogranicza się ona do jednego narzędzia ani konkretnego modelu AI. Jest to problem systemowy związany z tym, jak budujemy autonomicznych agentów, którzy wchodzą w interakcję z zewnętrznymi źródłami danych. W zasadzie dajemy tym agentom przepustkę VIP do naszych najbardziej wrażliwych systemów bez bramkarza przy drzwiach, który sprawdzałby identyfikatory.
Łagodzenie ryzyka integracji agentów AI
W ramach przeciwdziałania organizacje muszą przemyśleć sposób, w jaki pozwalają agentom AI na interakcję z usługami stron trzecich. Pomijając poprawki, najskuteczniejszą obroną jest przejście w stronę modelu zerowego zaufania (Zero Trust) dla kontekstu AI. Tylko dlatego, że dane pochodzą z oficjalnego API, nie oznacza to, że są bezpieczne do wykonania.
Programiści powinni wystrzegać się każdego agenta AI, który prosi o pozwolenie na uruchomienie dowolnego kodu bez ręcznego nadzoru. Jeśli używasz narzędzi takich jak Claude Code lub Cursor, musisz zachować wysoki poziom zdrowej paranoi. Przeglądaj polecenia, które proponuje agent, zanim naciśniesz klawisz Enter. Jeśli agent sugeruje rozwiązanie błędu Sentry, które wiąże się z uruchomieniem skryptu powłoki, którego nie napisałeś, zatrzymaj się i najpierw zweryfikuj błąd w panelu kontrolnym Sentry.
Dla organizacji priorytetem jest audyt kodu publicznego pod kątem ujawnionych kluczy DSN. Chociaż klucze Sentry DSN służą tylko do zapisu, wyraźnie stanowią ryzyko krytyczne dla misji, gdy w grę wchodzą agenci AI. Traktowanie tych kluczy z taką samą starannością jak prywatnego klucza API jest niezbędnym krokiem. W konsekwencji zespoły ds. bezpieczeństwa powinny zaktualizować swoje modele zagrożeń, aby uwzględnić agentów AI jako potencjalny wektor wykonania dla danych zewnętrznych.
Kluczowe wnioski dla bezpiecznej adopcji AI
Aby chronić swoje środowisko programistyczne przed Agentjackingiem i podobnymi atakami typu injection, rozważ następujące kroki:
- Przeprowadź audyt wszystkich publicznych repozytoriów i wdrożeń frontendowych pod kątem ujawnionych kluczy Sentry DSN i dokonaj rotacji wszystkich kluczy znalezionych w czystym tekście.
- Skonfiguruj agentów kodujących AI tak, aby wymagali wyraźnej ręcznej zatwierdzenia dla każdego polecenia powłoki lub zmiany w systemie plików.
- Wyłącz automatyczne pobieranie danych z Sentry lub innego zewnętrznego kontekstu w narzędziach AI, chyba że aktywnie debugujesz znany problem.
- Edukuj programistów na temat ryzyka związanego z prompt injection i wstrzykiwaniem danych poprzez zaufane integracje stron trzecich.
- Wdróż ziarniste uprawnienia dla agentów AI, aby zapewnić, że nie mogą oni uzyskać dostępu do wrażliwych plików, takich jak .env lub .git/config, bez konkretnego powodu.
Znajdujemy się w okresie szybkiej adopcji AI, w którym szybkość rozwoju często wyprzedza rozwój ram bezpieczeństwa. Agentjacking przypomina, że każda nowa integracja tworzy nową ścieżkę dla atakującego. Agenci, którym ufamy, że ułatwią nam życie, są tylko tak bezpieczni, jak dane, którymi ich karmimy.
Źródła: Tenet Security Research Blog, Sentry Official Documentation, Model Context Protocol Specification, NIST AI Risk Management Framework.
Zastrzeżenie: Niniejszy artykuł służy wyłącznie celom informacyjnym i edukacyjnym i nie zastępuje profesjonalnego audytu cyberbezpieczeństwa ani usługi reagowania na incydenty.



Do zobaczenia po drugiej stronie.
Nasze kompleksowe, szyfrowane rozwiązanie do poczty e-mail i przechowywania danych w chmurze zapewnia najpotężniejsze środki bezpiecznej wymiany danych, zapewniając bezpieczeństwo i prywatność danych.
/ Utwórz bezpłatne konto
