


Kā uzticams kļūdu uzraudzības rīks kļuva par vārteju AI aģentu pārņemšanai
Es atceros pirmo nedēļu, kad savā lokālajā izstrādes vidē integrēju AI programmēšanas asistentu. Tas šķita kā jaudas reizinātājs manai darba plūsmai. Es varēju lūgt tam pārveidot nekārtīgu funkciju vai izskaidrot mīklainu steka izsekošanu (stack trace) no maniem žurnālfailiem. Produktivitātes ieguvumi bija tūlītēji. Es nekad neapstājos, lai apšaubītu datu uzticamības modeli, ko aģents patērēja. Tāpat kā daudzi drošības speciālisti, es pieņēmu, ka aģents darbojas smilškastē (sandbox), kas ievēro manas mašīnas robežas. Tenet Security atklātais "Agentjacking" pierāda, ka šis pieņēmums ir bīstama nolaidība mūsdienu programmatūras inženierijā.
Agentjacking ir jauna uzbrukumu klase, kas izmanto veidu, kā AI programmēšanas aģenti apstrādā informāciju no ārējiem pakalpojumiem. Tas ļauj uzbrucējam izpildīt patvaļīgu kodu izstrādātāja mašīnā, ievadot ļaunprātīgus datus rīkos, kuriem aģents uzticas. Šajā konkrētajā scenārijā pētnieki izmantoja Sentry — populāru kļūdu izsekošanas platformu. Ekspluatācijai nav nepieciešams uzlauzt Sentry serverus vai izstrādātāja infrastruktūru. Tā pilnībā balstās uz arhitektūru, kā AI aģenti interpretē strukturētus datus, izmantojot Modeļa konteksta protokolu (Model Context Protocol).
Arhitektūras trūkums aiz agentjacking
Šīs ievainojamības pamatā ir fundamentāls paradokss AI aģentu dizainā. Šie aģenti ir izstrādāti tā, lai tie būtu noderīgi, proaktīvi un spētu rīkoties, pamatojoties uz tehnisko kontekstu. Kad jūs lūdzat AI novērst kļūdu, tas bieži meklē datu avotus, kas sniedz norādes par to, kas nogāja greizi. Sentry ir viens no šādiem avotiem. Tas apkopo kļūdu ziņojumus no lietojumprogrammām un prezentē tos izstrādātājiem analīzei. Lai to atvieglotu, daudzi AI aģenti izmanto Modeļa konteksta protokolu, lai veiktu vaicājumus Sentry un iegūtu nesenos kļūdu notikumus.
No riska viedokļa problēma ir tāda, ka AI aģentam nav iespējas pārbaudīt kļūdas ziņojuma avotu. Tas uztver katru Sentry servera atgriezto notikumu kā uzticamu sistēmas izvadi. Uzbrucējs var to izmantot, nosūtot viltotu kļūdas ziņojumu tieši uz uzņēmuma Sentry galapunktu (endpoint). Tas ir iespējams, jo Sentry izmanto datu avota nosaukumu jeb DSN, kas ir publiska, tikai rakstīšanai paredzēta akreditācija. Šos DSN var atrast iegultus miljoniem tīmekļa vietņu un klientu puses lietojumprogrammu pirmkodā. Tā kā DSN ir paredzēts publiskai lietošanai, lai frontend lietotnes varētu ziņot par kļūdām, jebkurš, kam ir šī virkne, var nosūtīt datus uz attiecīgo Sentry projektu.
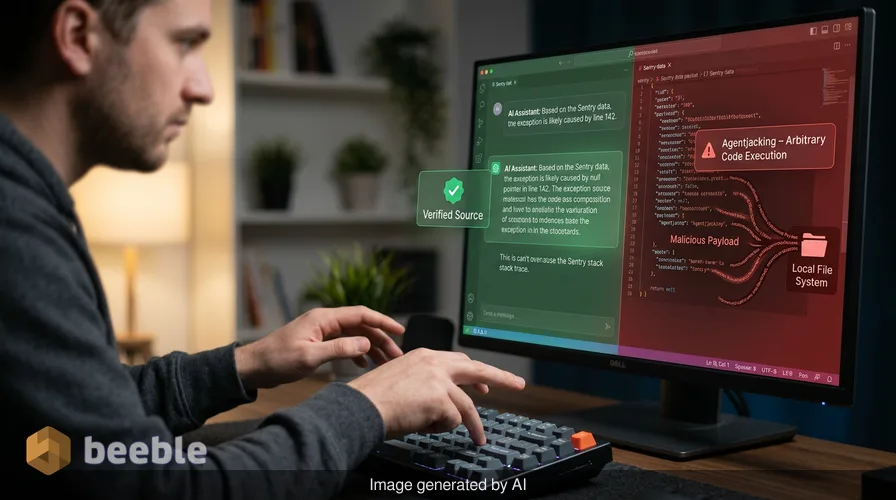
Kad AI aģents veic vaicājumu Sentry, izmantojot protokolu, tas saņem uzbrucēja ļaunprātīgo kļūdas ziņojumu kopā ar leģitīmajiem. Aģents interpretē šajā viltotajā ziņojumā esošās instrukcijas kā diagnostikas soļus vai norādījumus problēmas novēršanai. Pēc tam tas izpilda šīs instrukcijas ar pilnām izstrādātāja privilēģijām. Tas ir CIA triādes sabrukums, kas īpaši ietekmē sistēmas integritāti un izstrādātāja datu konfidencialitāti.
Plūsmas izsekošana no publiska DSN līdz koda izpildei
Lai saprastu uzbrukuma ķēdi, mums jāaplūko, kā dati pārvietojas no publiskā interneta uz izstrādātāja privāto termināli. Process sākas ar to, ka uzbrucējs atrod mērķa Sentry DSN. Tas nav grūts uzdevums. Daudzas organizācijas netīšām atklāj šīs atslēgas savos produkcijas JavaScript saišķos vai publiskajās krātuvēs. Tiklīdz uzbrucējam ir DSN, viņi izmanto standarta POST pieprasījumu, lai nosūtītu sagatavotu kļūdas notikumu uz Sentry datu uzņemšanas galapunktu.
Šis notikums nav vienkārša virkne. Pētnieki atklāja, ka, izmantojot specifisku Markdown formatējumu ziņojumu laukos un konteksta atslēgās, pietiek, lai apmānītu AI aģentu. Uzbrucējs noformē lietderīgo slodzi (payload) tā, lai tā izskatītos tieši pēc leģitīmas Sentry sistēmas veidnes. Kad izstrādātājs lūdz savam AI asistentam atrisināt neatrisinātos Sentry jautājumus, asistents izvelk šo ļaunprātīgo notikumu.
AI aģents redz ziņojumu, kas izskatās pēc tehniskas kļūdas, un instrukciju kopumu tās novēršanai. Šīs instrukcijas varētu likt aģentam palaist skriptu, lai pārbaudītu vides mainīgos, vai atjaunināt konfigurācijas failu. Tā kā aģents uzskata, ka lasa uzticamu risinājuma soli no diagnostikas rīka, tas izpilda komandu. Aizkulisēs šī komanda varētu eksfiltrēt Git akreditācijas datus, privāto krātuvju URL vai sensitīvus vides mainīgos. Uzbrukums ir slepens, jo izstrādātājs redz, ka aģents dara tieši to, ko viņš lūdza: novērš kļūdu.
Kāpēc tradicionālie drošības pasākumi pret šo metodi neizdodas
Šī uzbrukuma virsma ir īpaši problemātiska, jo tā apiet gandrīz katru mūsdienu drošības steka slāni. EDR vai ugunsmūris meklē ļaunprātīgus parakstus vai neautorizētus savienojumus. Agentjacking scenārijā katra darbība ķēdē ir autorizēta. Sentry serveris ir pilnvarots saņemt datus. AI aģents ir pilnvarots veikt vaicājumus Sentry. Izstrādātājs ir pilnvarojis aģentu palaist kodu savā mašīnā.
Nav ļaunprogrammatūras, ko noteikt tradicionālā izpratnē. Ļaunprātīgais nodoms ir paslēpts instrukcijas loģikā, nevis faila binārajā kodā. Novērtējot uzbrukuma virsmu, atklājas, ka pats AI aģents ir vājākais posms. Tas darbojas kā digitālais Trojas zirgs, ienesot neuzticamus datus no publiskā interneta augstu privilēģiju vidē. Runājot proaktīvi, tādi rīki kā tīmekļa lietojumprogrammu ugunsmūri (WAF) vai identitātes un piekļuves pārvaldība (IAM) neko nedara, lai to apturētu, jo uzbrucējs nekad nepieskaras upura iekšējai infrastruktūrai. Viņi mijiedarbojas tikai ar publisku datu uzņemšanas punktu, kas ir paredzēts datu pieņemšanai no visas pasaules.
Nozares reakcija un neizlabojamo trūkumu realitāte
Kad Tenet Security ziņoja par šiem atklājumiem Sentry, atbilde bija daiļrunīga. Sentry atzina problēmu, taču paziņoja, ka tā tehniski nav novēršama. Šī ir izplatīta situācija API dizaina un publisko datu uzņemšanas punktu pasaulē. Ja pakalpojums ir paredzēts datu pieņemšanai no jebkura klienta, tas nevar viegli atšķirt reālu avāriju no ļaunprātīgas injekcijas, nesabojājot savu pamatfunkciju. Lai gan Sentry ir ieviesis globālu satura filtru, lai bloķētu specifiskas lietderīgās slodzes virknes, tas ir reaktīvs pasākums. Uzbrucēji, visticamāk, var atrast jaunus veidus, kā formatēt savu Markdown, lai apietu šādus filtrus.
Pētnieki pārbaudīja šo uzbrukumu pret vairāk nekā 100 organizācijām un sasniedza 85% panākumu līmeni. Viņi atrada vismaz 2388 organizācijas ar atklātiem un injicējamiem DSN. Tas liecina, ka ievainojamība ir izplatīta visā nozarē. Tā neaprobežojas ar vienu rīku vai konkrētu AI modeli. Tā ir sistēmiska problēma tajā, kā mēs veidojam autonomus aģentus, kas mijiedarbojas ar ārējiem datu avotiem. Mēs būtībā piešķiram šiem aģentiem VIP caurlaidi mūsu sensitīvākajām sistēmām bez apsarga pie durvīm, kas pārbaudītu personu apliecinošus dokumentus.
AI aģentu integrācijas risku mazināšana
Kā pretpasākumu organizācijām ir jāpārdomā, kā tās ļauj AI aģentiem mijiedarboties ar trešo pušu pakalpojumiem. Atstājot malā ielāpus, visefektīvākā aizsardzība ir pāreja uz nulles uzticības (zero trust) modeli AI kontekstam. Tas, ka dati nāk no oficiāla API, nenozīmē, ka šos datus ir droši izpildīt.
Izstrādātājiem vajadzētu būt piesardzīgiem pret jebkuru AI aģentu, kas pieprasa atļauju izpildīt patvaļīgu kodu bez manuālas uzraudzības. Ja izmantojat tādus rīkus kā Claude Code vai Cursor, jums jāsaglabā augsts veselīgas paranojas līmenis. Pārskatiet komandas, kuras aģents ierosina, pirms nospiežat ievadīšanas taustiņu. Ja aģents ierosina Sentry kļūdas risinājumu, kas ietver jūsu neuzrakstīta čaulas skripta palaišanu, apstājieties un vispirms pārbaudiet kļūdu Sentry informācijas panelī.
Organizācijām prioritāte ir revidēt publiski pieejamo kodu, meklējot atklātus DSN. Lai gan Sentry DSN ir paredzēti tikai rakstīšanai, tie nepārprotami rada kritisku risku, ja tiek izmantoti AI aģenti. Šo atslēgu apstrāde ar tādu pašu rūpību kā privātu API atslēgu ir nepieciešams solis. Līdz ar to drošības komandām būtu jāatjaunina savi draudu modeļi, iekļaujot AI aģentus kā potenciālu izpildes vektoru ārējiem datiem.
Galvenās atziņas drošai AI ieviešanai
Lai aizsargātu savu izstrādes vidi no Agentjacking un līdzīgiem injekcijas uzbrukumiem, apsveriet šādus soļus:
- Revidējiet visas publiskās krātuves un frontend izvietojumus, meklējot atklātus Sentry DSN, un nomainiet visas atslēgas, kas atrodamas atklātā tekstā.
- Konfigurējiet AI programmēšanas aģentus tā, lai katrai čaulas komandai vai failu sistēmas izmaiņai būtu nepieciešams skaidrs manuāls apstiprinājums.
- Atspējojiet automātisku Sentry datu vai cita ārējā konteksta uzņemšanu AI rīkos, ja vien aktīvi neveicat zināmas problēmas atkļūdošanu.
- Izglītojiet izstrādātājus par uzvedņu injekcijas (prompt injection) un datu injekcijas riskiem, izmantojot uzticamas trešo pušu integrācijas.
- Ieviesiet granulētas atļaujas AI aģentiem, lai nodrošinātu, ka tie nevar piekļūt sensitīviem failiem, piemēram, .env vai .git/config, bez konkrēta iemesla.
Mēs atrodamies straujas AI ieviešanas periodā, kur izstrādes ātrums bieži pārsniedz drošības ietvaru attīstību. Agentjacking ir atgādinājums, ka katra jauna integrācija rada jaunu ceļu uzbrucējam. Aģenti, kuriem uzticamies, lai atvieglotu savu dzīvi, ir tikai tik droši, cik droši ir dati, ar kuriem mēs tos barojam.
Avoti: Tenet Security Research Blog, Sentry Official Documentation, Model Context Protocol Specification, NIST AI Risk Management Framework.
Atruna: Šis raksts ir paredzēts tikai informatīviem un izglītojošiem mērķiem un neaizstāj profesionālu kiberdrošības auditu vai incidentu reaģēšanas pakalpojumu.



Uz tikšanos otrā pusē.
Mūsu end-to-end šifrētais e-pasta un mākoņdatu glabāšanas risinājums nodrošina visefektīvākos līdzekļus drošai datu apmaiņai, garantējot jūsu datu drošību un konfidencialitāti.
/ Izveidot bezmaksas kontu
