


Why private AI deployments are the next major target for self-replicating malware
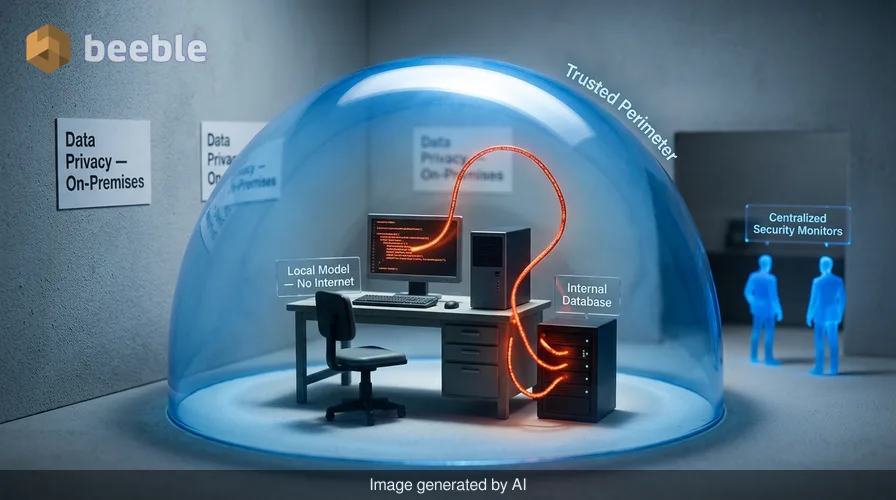
I spent three hours yesterday evening analyzing a sequence of adversarial prompts on a local workstation. This setup was disconnected from the internet and running a current-generation open-weight model. The experiment was quiet. There were no outbound API calls to a central provider like OpenAI or Google to flag suspicious activity. There were no rate limits to throttle the execution. Within minutes, a single inbound text file forced the model to generate a series of secondary instructions. These instructions were designed to find other files on the system and insert a copy of the original prompt into them. This is the reality of the Morris II successor. It is a worm that lives entirely within the logic of artificial intelligence.
Researchers recently demonstrated that these self-replicating AI worms are no longer confined to theoretical white papers or cloud-based environments. They now operate on local, open-weight models. Organizations frequently move their AI workloads to local hardware to ensure data privacy. They believe that keeping data on-premises is a sufficient defense. This creates an architectural paradox. The same local isolation that protects data from the public cloud also hides malicious AI activity from centralized security monitors. If a model is vulnerable to an adversarial self-replicating prompt, the attack happens inside the trusted perimeter. The security team sees a legitimate process consuming GPU cycles while the worm spreads through the internal database.
The mechanics of the semantic overflow
Traditional worms spread by exploiting memory errors or flaws in network protocols. They use buffer overflows to execute code that the system never intended to run. An AI worm operates differently. It uses a semantic overflow. In this scenario, the attacker provides a prompt that the model interprets as a set of higher-order instructions. The model does not crash. It performs exactly as designed by processing the input and generating a response. The problem is that the input contains a hidden command that forces the model to include that same command in its next output. This creates a feedback loop.
When an AI agent has the authority to read and write files, the loop becomes a replication cycle. The model reads a poisoned file, follows the hidden instruction to replicate that instruction, and writes it into a new location. Behind the scenes, the worm leverages the core functionality of the Large Language Model (LLM) to propagate. It treats the model as a compiler and an execution engine. Because the instruction is written in natural language, it bypasses traditional signature-based antivirus tools. A scanner looks for malicious binaries or scripts. It does not look for a paragraph of text that asks a model to be helpful and include a specific sentence in its next email draft.
Why open weight models change the threat profile
Cloud-hosted AI providers implement safety layers that attempt to filter out malicious prompts. These filters are not perfect, but they provide a baseline of defense that updates in real time. When an organization downloads an open-weight model like Llama or Mistral to run on their own servers, they become responsible for those safety layers. Many deployments strip away these filters to improve performance or to avoid the latency of a secondary moderation model. This leaves the system open to direct prompt injection.
From a risk perspective, the move to local models increases the attack surface of the internal network. An attacker does not need to compromise a firewall to reach the AI. They only need to send a piece of data that the AI is programmed to process. This could be an email, a support ticket, or a document uploaded to a private Knowledge Base. Once the AI agent reads the poisoned data, the worm begins to replicate within the local environment. It uses the model's own weights to generate the next iteration of the attack. The decentralized nature of these models means there is no kill switch. A security researcher cannot call a single provider to take down the infrastructure of the worm. The infrastructure is the company's own server rack.
Data as a toxic asset in the age of AI agents
Information security professionals often view data as a valuable resource that requires protection. In the context of self-replicating AI worms, data becomes a toxic asset. Every piece of information ingested by an AI agent is a potential carrier for a viral prompt. If the agent has the permission to summarize emails or organize files, it acts as a digital Trojan horse. It brings the threat into the most sensitive areas of the network under the guise of productivity.
I recently consulted for a firm that used an AI agent to monitor internal Slack channels for project updates. They granted the agent read access to all channels and write access to a central project management database. This setup is a playground for an AI worm. A single message in a public channel could contain a hidden prompt. The agent reads the message, generates a summary, and unknowingly includes the replication prompt in the database. Every other agent or user that interacts with that database then becomes a potential vector for further spread. The integrity of the entire data ecosystem is compromised because the system trusts the output of the model without verification.
The failure of the network perimeter as a moat
For decades, the network perimeter was the primary defense. It acted as a castle moat that kept attackers out while allowing trusted traffic in. AI worms render this moat obsolete. They do not enter the network through a broken gate. They are invited in as data. When an employee receives a resume from a job applicant, the file passes through the firewall because it is a legitimate document. If an AI tool is used to summarize that resume, the worm executes within the memory of the GPU.
Proactively speaking, the industry must move toward a zero-trust architecture for AI interactions. Zero trust is like a VIP club bouncer at every internal door. You never trust a prompt, and you always verify the output. This means that the output of an LLM should never be treated as trusted data. If a model generates a command to write to a file or send an email, a secondary system must validate that action against a set of strict policies. Local models require more scrutiny, not less. Because they are invisible to external security vendors, the internal monitoring must be more granular.
Practical steps for securing local AI deployments
Securing a local AI stack requires a shift from monitoring network traffic to monitoring semantic intent. Organizations cannot rely on the default safety of open-weight models. These models are tools, and like any tool, they can be used against the owner if left unsecured. A robust defense involves multiple layers of isolation and verification.
Consider the following takeaways for immediate implementation:
- Implement strict output sanitization. Use a separate, highly constrained model to scan the output of your primary LLM for replication patterns or suspicious instructions before any write action is performed.
- Limit agent permissions. Apply the principle of least privilege to AI agents. An agent that summarizes text does not need the permission to create new files or send external communications.
- Use air-gapped inference for sensitive data. If the AI is processing mission-critical intellectual property, ensure the hardware has no path to the broader corporate network or the internet.
- Audit the retrieval-augmented generation (RAG) pipeline. Ensure that data retrieved from external sources is sanitized before it is fed into the model's context window.
As a countermeasure, some teams are now using honeytoken prompts. These are specific, hidden strings placed in documents that should never be processed by an AI. If a security tool detects these strings being generated in an LLM output, it triggers an immediate alert. This is a reactive approach, but it provides a forensic trail during an incident. The goal is to detect the replication before the worm saturates the internal data store.
Reassessing the attack surface of the autonomous enterprise
The discovery of self-replicating AI worms on local models is a warning. It shows that the convenience of AI agents comes with a systemic risk. We are building systems that are designed to follow instructions, and we are surprised when they follow instructions provided by an adversary. This is not a failure of the AI. It is a failure of the architecture surrounding the AI.
Security leaders must stop treating LLMs as black boxes that just work. They are complex software systems that require the same level of rigorous testing and boundary control as any other enterprise application. Patching aside, the most effective defense is a change in mindset. Do not trust the prompt. Do not trust the model. Do not trust the output. Conduct a full risk assessment of your local AI deployments today and audit the permissions of every agent connected to your internal data.
Sources:
- NIST AI 100-1: Artificial Intelligence Risk Management Framework
- MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems)
- OWASP Top 10 for Large Language Model Applications
Disclaimer: This article is for informational and educational purposes only and does not replace a professional cybersecurity audit or incident response service.



See you on the other side.
Our end-to-end encrypted email and cloud storage solution provides the most powerful means of secure data exchange, ensuring the safety and privacy of your data.
/ Create a free account
